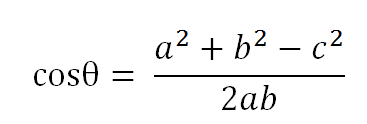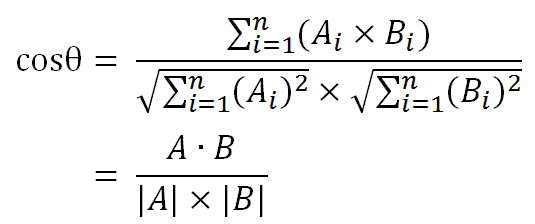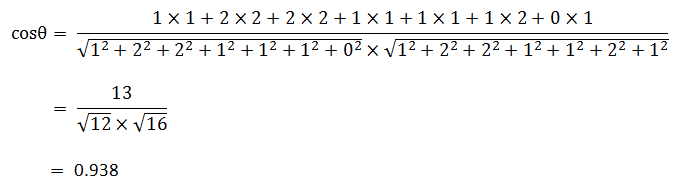扫描器之文本相似度计算 前言 被师傅问到这样一些情况:当使用扫描器去扫描页面,发现有些页面如403是自定义的页面,这种情况该怎么办,我当时想的是,直接去获取context里面的文本,有403 的话,可以跳过。但是,师傅好像不是这样说的,和泛解析差不多的思路。都可以用文本相似度来解决。
文本相似度算法 余弦相似性 首先,我们先来简单看一下,什么是余弦相似性
先来看两个句子:
句子A:我喜欢看电视,不喜欢看电影
句子B:我不喜欢看电视,也不喜欢看电影
如果要计算上面两句话的相似度的话:
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
1. 分词
句子A:我/喜欢/看/电视,不/喜欢/看/电影
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影
2. 列出所有的词
我,喜欢,看,电视,电影,不,也
3. 计算词频
句子A:我:1,喜欢:2,看:2,电视:1,电影:1,不:1,也:0
句子B:我:1,喜欢:2,看:2,电视:1,电影:1,不:2,也:1
4. 写出词频向量
句子A:[1,2,2,1,1,1,0]
句子B:[1,2,2,1,1,2,1]
到这里,问题就变成了如何计算这两个向量的相似程度
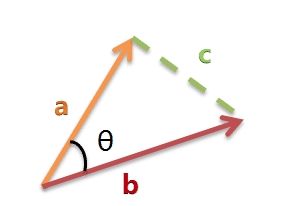
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, …])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成了直角,方向完全不相似,如果角度为180°,意味着方向相反,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。
以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ,余弦定理告诉我们,可以用下面的公式求得:
数学家已经证明,余弦的这种计算方法对n维向量也成立。
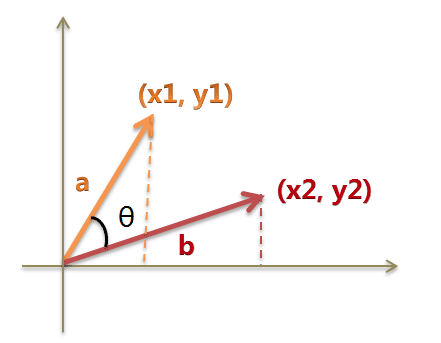
假定A和B是两个n维向量,A是 [A1, A2, …, An] ,B是 [B1, B2, …, Bn] ,则A与B的夹角θ的余弦等于:
使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫”余弦相似性”。所以,上面的句子A和句子B是很相似的,事实上它们的夹角大约为20.3度。
由此,我们就得到了”找出相似文章”的一种算法:
1、使用TF-IDF算法,找出两篇文章的关键词;
2、每篇文章各取出若干个关键词(比如20个),合并成一个集合,计算每篇文章对于这个集合中的词的词频(为了避免文章长度的差异,可以使用相对词频);
3、生成两篇文章各自的词频向量;
4、计算两个向量的余弦相似度,值越大就表示越相似。
SimHash SimHash为Google处理海量网页的采用的文本相似判定方法。该方法的主要目的是降维,即将高维的特征向量映射成f-bit的指纹,通过比较两篇文档指纹的汉明距离来表征文档重复或相似性。
备注:此处f-bit指纹,可以根据应用需求,定制为16位、32位、64位或者128位数等。
simhash算法分为5个步骤:分词、hash、加权、合并、降维,具体过程如下所述:
1. 分词 如上面的余弦相似性的步骤类似
2. hash 通过hash函数计算各个特征向量的hash值,hash值为二进制数01组成的n-bit签名。比如比如句子 A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0 中的 hash值Hash:
(喜欢)为100101,“电视”的hash值Hash(电视)为“101011”(当然实际的值要比这个复杂,hash串比这要长)
就这样,字符串就变成了一系列数字。
3. 加权 通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“喜欢”的hash值为“100101”,把hash值从左到右与权重相乘,如果为1则乘以1 ,如果是0则曾以-1 ,喜欢的权重是2 计算为“2 -2 -2 2 -2 2”;
4. 合并 把上面所有各个单词算出来的序列值累加,变成只有一个序列串。比如 “喜欢”的“2 -2 -2 2 -2 2”,“电视”的 “ 1 -1 1 -1 1 1”, 把每一位进行累加, (2+1)+(-2-1)+(-2+1)+(2-1)+(-2+1)+(2+1)=3 -3 -1 1 -1 3
5. 降维 把4步算出来的 “3 -3 -1 1 -1 3” 变成 0 1 串,形成我们最终的simhash签名。 如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 0 1 0 1”。这样就得到了每篇文档的SimHash签名值
6. 海明距离 海明距离的求法:异或时,只有在两个比较的位不同时其结果是1 ,否则结果为0,两个二进制“异或”后得到1的个数即为海明距离的大小。
根据经验值,对64位的 SimHash值,海明距离在3以内的可认为相似度比较高。
根据经验值,对64位的 SimHash值,海明距离在3以内的可认为相似度比较高。
比如:
A:我喜欢看电视,不喜欢看电影 其hash值为 1 0 0 1 0 1
B:我也很喜欢看电视,但不喜欢看电影 其hash值为 1 0 1 1 0 1
两者 hash 异或运算结果 001000,统计结果中1的个数是1,那么两者的海明距离就是1,说明两者比较相似。
下面是python代码的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 class simhash : def __init__ (self, tokens='' , hashbits=128 ): self.hashbits = hashbits self.hash = self.simhash(tokens) def simhash (self, tokens ): v = [0 ] * self.hashbits tokens_hash = [self.string_hash(x) for x in tokens] for t in tokens_hash: for i in range (self.hashbits): bitmask = 1 << i if t & bitmask: v[i] += 1 else : v[i] -= 1 fingerprint = 0 for i in range (self.hashbits): if v[i] >= 0 : fingerprint += 1 << i return fingerprint def hamming_distance (self, other ): xorResult = (self.hash ^ other.hash ) hashbit128 = ((1 << self.hashbits) - 1 ) x = xorResult & hashbit128 count = 0 while x: count += 1 x &= x - 1 return count def similarity (self, other ): a = float (self.hash ) b = float (other.hash ) if a > b: return b / a else : return a / b def string_hash (self, source ): if source == "" : return 0 else : result = ord (source[0 ]) << 7 m = 1000003 hashbit128 = ((1 << self.hashbits) - 1 ) for c in source: temp = (result * m) ^ ord (c) result = temp & hashbit128 result ^= len (source) if result == -1 : result = -2 return result if __name__ == '__main__' : s = '你 知道 里约 奥运会,媒体 玩出了 哪些 新花样?' hash1 = simhash(s.split()) print hash1.__str__() s = '我不知道 里约 奥运会,媒体 玩出了 哪些 新花样' hash2 = simhash(s.split()) print hash2.__str__() s = '视频 直播 全球 知名 媒体 的 战略 转移' hash3 = simhash(s.split()) print (hash1.hamming_distance(hash2), " " , hash1.similarity(hash2)) print (hash1.hamming_distance(hash3), " " , hash1.similarity(hash3)) print (hash2.hamming_distance(hash3), " " , hash2.similarity(hash3))
go语言扫描器雏形 期间,出现一些问题,比如,百度的首页,使用http协议访问的时候,会出现一些问题,原因是百度会随机加载js,他们的名称不同,通过获取response.body的信息自然也变得不能接受。应该算百度的反爬策略,目前为止,,好像除了百度首页,,我还没遇到其他的,,就先放一放吧。。。。等以后有眉头的再搞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 package mainimport ( "fmt" "io/ioutil" "log" "math/big" "net/http" "strings" ) type SimHash struct { IntSimHash *big.Int HashBits int } func (s *SimHash) hase_v := new (big.Int) c_w := hase_v.Xor(hash, other) fbIng := big.NewInt(1 ) fbIng.Lsh(fbIng, uint (s.HashBits)) bit_big := new (big.Int) t_mak := bit_big.Sub(fbIng, big.NewInt(1 )) c_result := new (big.Int) c_result.And(c_w, t_mak) tot := big.NewInt(0 ) for c_result.Cmp(big.NewInt(0 )) > 0 { tot.Add(tot, big.NewInt(1 )) ts := new (big.Int) ts.Sub(c_result, big.NewInt(1 )) c_result.And(c_result, ts) } return tot } func (s *SimHash) float64 { a := new (big.Rat) a.SetInt(hash) b := new (big.Rat) b.SetInt(other) val := new (big.Rat) if a.Cmp(b) > 0 { val.Quo(b, a) f, _ := val.Float64() return f } val.Quo(a, b) f, _ := val.Float64() return f } func (s *SimHash) string ) *big.Int { m := strings.Split(str, "," ) token_int := make ([]int , s.HashBits) for i := 0 ; i < len (m); i++ { temp := m[i] t := s.Hash(temp) for j := 0 ; j < s.HashBits; j++ { fbIng := big.NewInt(1 ) bitMask := fbIng.Lsh(fbIng, uint (j)) statusBig := new (big.Int) statusBig.And(t, bitMask) if statusBig.Cmp(big.NewInt(0 )) != 0 { token_int[j] += 1 } else { token_int[j] -= 1 } } } fingerprint := big.NewInt(0 ) for i := 0 ; i < s.HashBits; i++ { if token_int[i] >= 0 { oneBig := big.NewInt(1 ) tbig := big.NewInt(0 ) fingerprint.Add(fingerprint, tbig.Lsh(oneBig, uint (i))) } } return fingerprint } func params () s = &SimHash{} s.HashBits = 128 return s } func (s *SimHash) string ) *big.Int { if token == "" { return big.NewInt(0 ) } else { bigIntToken := big.NewInt(int64 (token[0 ])) funit := new (big.Int) x := funit.Lsh(bigIntToken, 7 ) m := big.NewInt(1000003 ) mslB := big.NewInt(1 ) mask := mslB.Lsh(mslB, uint (s.HashBits)) tsk_b := mask.Sub(mask, big.NewInt(1 )) for i := 0 ; i < len (token); i++ { tokens := big.NewInt(int64 (token[i])) x.Mul(x, m) x.Xor(x, tokens) x.And(x, tsk_b) } x = x.Xor(x, big.NewInt(int64 (len (token)))) if x == big.NewInt(-1 ) { x = big.NewInt(-2 ) } return x } } func crawl (url string ) string ) { resp,err := http.Get(url) if err != nil { log.Fatalln(err) } defer resp.Body.Close() body,err := ioutil.ReadAll(resp.Body) response := string (body) fmt.Println(response) return response } func main () str := crawl("https://www.baidu.com" ) str2 := crawl("https://www.baidu.com" ) s := params() hash := s.Simhash(str) hash2 := s.Simhash(str2) sm := s.Similarity(hash, hash2) fmt.Println(sm) if sm > 0.85 { fmt.Println("此页面相似" ) }else { fmt.Println("此页面不相似" ) } }
参考文章 https://www.cnblogs.com/shaosks/p/9121774.html